【Google Analytics】正確なデータを取得するために必要な8つの初期設定(前編)

多くのWebサイトで導入されているアクセス解析ツール「Google Analytics」。アカウントを作成・タグを発行し、解析対象サイトのHTMLにタグを埋め込むだけという導入しやすさが特徴です。
ただし、これだけでは正確なデータを取得できません。Webサイトの改善や施策を検討する上で、ログデータの正確さが重要になってきます。
そこで今回は、より正確なデータを取得するために、事前にやっておくべき8つの設定ポイントを2回に分けてご紹介していきます。
INDEX
1)デフォルトのURL「URLを統一する」
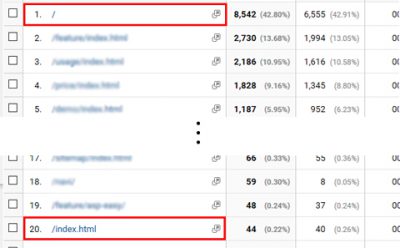
ページ別一覧での重複した状態
(行動>サイトコンテンツ>すべてのページ)
「http://abc.com/」と「http://abc.com/index.html」のように同じページであっても、それぞれのURLでアクセスできる場合、Google Analyticsでは別々のページとしてカウントされてしまいます。
これではトップページを閲覧したユーザーの正確なデータを集計することはできません。
同一のページとしてカウントするために、ビュー設定にある「デフォルトのページ」で[index.html]と入力して設定する必要があります。
設定方法
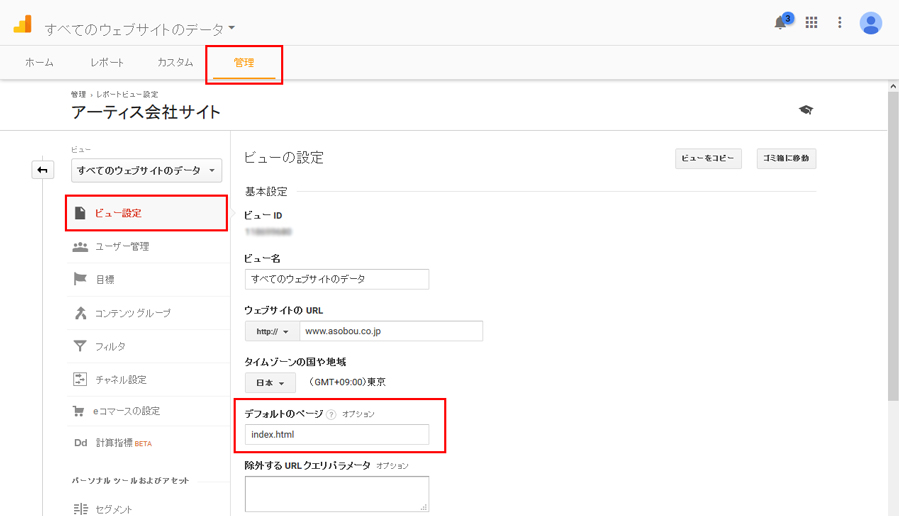
Google Analytics管理画面(管理>ビュー設定)
- 「管理」タブにある「ビュー設定」をクリックします。
- 「デフォルトのページ」項目でindex.htmlと入力します。
- 最後に画面下にある「保存」ボタンをクリックします。
※例では[index.html]としていますが、サイトによっては[index.php]や[index.htm]の場合もありますので、管理するサイトの仕様に応じて設定してください。
2)タイムゾーンの国や地域「集計する時間を正しく設定する」
「タイムゾーンの国や地域」とは、トラッキング対象のサイトを閲覧するユーザーの閲覧日時ではなく、集計する際にどの国や地域の時間に変換して集計するかを決める設定です。
例えば、日本時間で集計したいのに設定が別の国や地域になっている場合、実際は日本時間の18:00にアクセスがあった場合でも、設定された国や地域の時間に変換されてしまうため正確な日時を把握することができなくなります。
また、間違っていたことに気づき、設定を変更してもそれまでに取得されたデータは変更されません。
意外と見落としてしまう項目なのでしっかりと確認しておきましょう。
設定方法
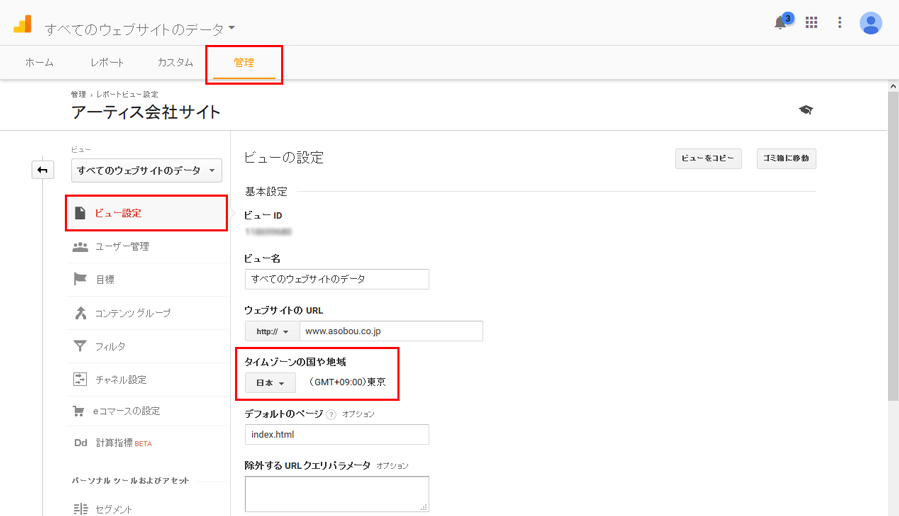
Google Analytics管理画面(管理>ビュー設定)
- 「管理」タブにある「ビュー設定」をクリックします。
- 「タイムゾーンの国や地域」項目で日本を選択します。※国内の時間帯に合わせたい場合
- 最後に画面下にある「保存」ボタンをクリックします。
3)ボットのフィルタリング「より人間によるアクセスデータに近づける」
Webサイトには、人間以外にもクローラーやスパイダーと呼ばれるロボットもアクセスします。一般的に認知されているロボットは、検索エンジンのクローラーです。(クローラーとは?SEOの基本:検索エンジンの仕組みを理解しよう!)
アクセス解析は「ユーザー=人間」の行動を把握するためのツールです。ロボットからのアクセスが含まれてしまうと正確なデータ分析が難しくなります。
そこで、より人間によるアクセスデータに近づけるために、ビュー設定にある「ボットのフィルタリング」で「既知のボットやスパイダーからのヒットをすべて除外します」にチェックを入れておきましょう。
設定方法
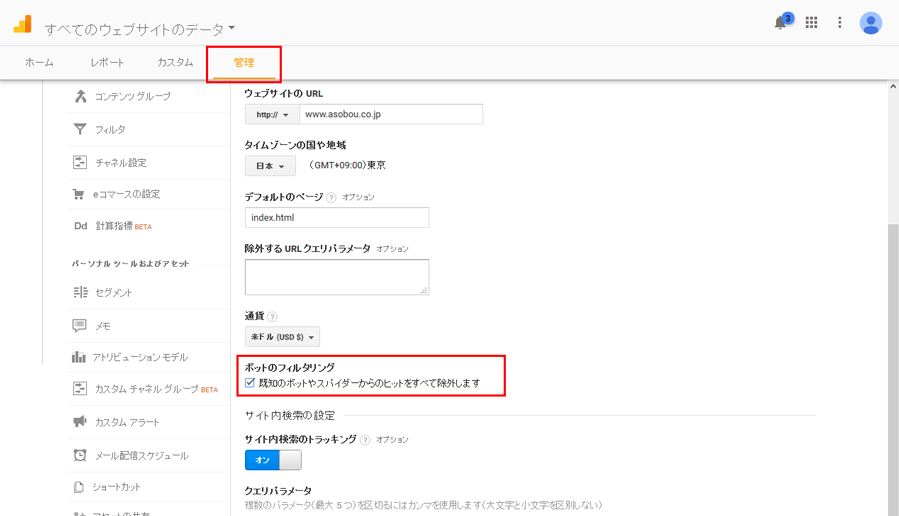
Google Analytics管理画面(管理>ビュー設定)
- 「管理」タブにある「ビュー設定」をクリックします。
- 「ボットのフィルタリング」項目で既知のボットやスパイダーからのヒットをすべて除外しますにチェックを入れます。
- 最後に画面下にある「保存」ボタンをクリックします。
最近では、アクセス解析データに悪意を持って参照元情報を残す「リファラースパム」が増加しています。このリファラースパムを除外するためにも「ボットのフィルタリング」は効果的です。しかし、完全に除外するためには、さらなる設定が必要になりますのでまた改めて解説したいと思います。
4)サイト内検索のトラッキング 「サイト内検索のキーワードを取得する」
サイト内検索は、ユーザーが知りたい情報をサイト内から探すための機能です。多くのWebサイトで実装されているかと思いますが、ユーザーがサイト内検索で検索したキーワードを把握できていますか?
ビュー設定にある「サイト内検索の設定」を行うことで、ユーザーの検索キーワードやキーワード毎の行動データを取得することができます。サイト内検索で使用されているキーワードから、Webサイトに訪れるユーザーのニーズを伺い知ることができますので、ぜひ可視化したい情報です。
設定方法
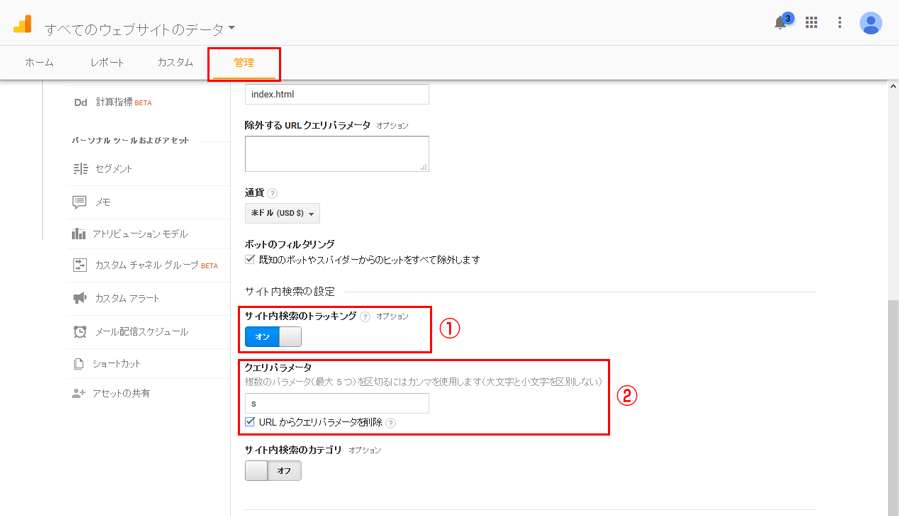
Google Analytics管理画面(管理>ビュー設定)
- 管理>ビュー設定画面にある「サイト内検索のトラッキング」をオンの状態にします。
- クエリパラメータの入力欄にサイト内検索のクエリパラメータを入力します。(注釈参照)
管理画面のレポートページでURLの種類を増やしたくない場合は、URLからクエリパラメータを削除にチェックを入れておくと良いです。 - 最後に画面下にある「保存」ボタンをクリックします。
<注釈:クエリパラメータの確認方法>
サイト内検索のクエリパラメーターは、サイト内検索の結果ページURLで確認できます。
サイト内検索の結果ページURLが、「https://www.asobou.co.jp/blog/?s=googleアナリティクス」の場合、[?]の後に続く[s]がクエリパラメータとなります。ワードプレスで作成されたサイトの場合は[s]になりますが、サイト内検索の仕様によってクエリパラメータが異なりますので、実際に検索を行ってブラウザに表示されるURLをご確認ください。
まとめ
1)デフォルトのURL 「URLを統一する」
2)タイムゾーンの国や地域 「集計する時間を正しく設定する」
3)ボットのフィルタリング 「より人間によるアクセスデータに近づける」
4)サイト内検索のトラッキング 「サイト内検索のキーワードを取得する」
前編では、「ビュー設定」で設定できる内容について説明しました。
どれも簡単に設定できる内容なので、運用開始前に必ず設定しておくことをおすすめします。
次回後編では、残りの4つについて説明します。
この記事を書いた人

- 事業開発部 次長
-
印刷会社の営業を経て、2008年にアーティスへ入社。webディレクターとして多くの大学・病院・企業のwebサイト構築・コンサルティングに携わる。2018年より事業開発部として新規サービスの企画立案・マーケティング・UI設計・開発に従事している。
資格:Google広告認定資格・Yahoo!プロモーション広告プロフェッショナル
この執筆者の最新記事


最新記事






FOLLOW US
最新の情報をお届けします
- facebookでフォロー
- Twitterでフォロー
- Feedlyでフォロー