SEOの基本:検索エンジンの仕組みを理解しよう!
日本国内の主要な検索エンジンである「Google検索」と「Yahoo!検索」。
ご存じの方も多いかもしれませんが、この2つの検索エンジンはどちらもGoogle社が提供する検索技術を使用しています。各社の扱う事業やポリシーにより検索順位には多少違いがありますが、ここではGoogleの検索エンジンの仕組みについて見ていきたいと思います。

検索エンジンの基本的な仕組み
検索エンジンは、「クローラー」「インデクサー」「サーチャー」のたった3つのプログラムで構成されています。
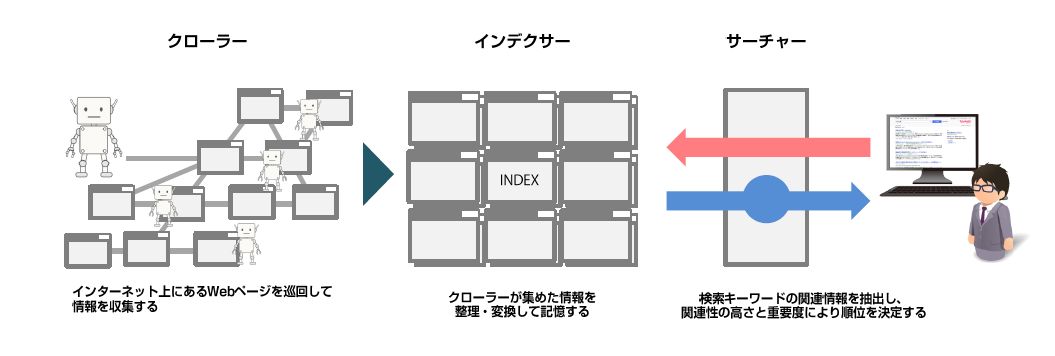
クローラー
インターネット上にあるWebページを巡回して情報を収集(クローリング)する。
インデクサー
クローラーが集めた情報を解析し、必要に応じて瞬時に取り出せるデーター形式に変換してデータベースに保存(インデックス)する。
サーチャー
ユーザーの検索キーワードを元にインデクサーがデータベースに保存した情報から関連情報を抽出し、関連性の高さと重要度により順位を決定した後に検索結果として送信する。
サーチャーで行われる、検索されたキーワードから関連した情報リストを作る行動を「クエリ実行」、そしてそのリストにあるWebページをランク付けするために用いられる仕組み・行動を「検索アルゴリズム」と呼びます。
検索エンジンの情報収集「クローリング」
インターネット上にあるWebページを含むデーターの収集はクローラーが行います。クローラーはインターネット上を巡回するプログラムです。
クローラーがWebサイト内を回遊して情報を収集する作業を「クローリング」と呼びます。クローリングされていない情報は、そもそも検索の対象となりえませんので、クローラーを自社のWebサイトに呼ぶことは検索エンジン対策の起点と言えます。
クローラーは、人がWebサイトを閲覧するときと同じようにページ内の情報を読み、リンクを辿って他のページ・サイトに移動していきます。Webページを構成するHTMLファイル内のリンクのほか、PDF、Wordなどのファイル内にあるリンクやJavaScriptで生成されるリンクも巡回の対象です。
検索エンジンの情報記憶「インデックス」
クローラーが収集した情報をインデクサーが整理・解析し、必要に応じて瞬時に取り出せるデーター形式に変換してデータベースに保存します。これを「インデックス」と呼びます。
インデクサーは人と違い、視覚で内容を理解することはできません。例えば、人が見た場合には、ページの先頭に大きく目立つように書かれた文字がタイトルだ、とわかっても、インデクサーには伝わりません。そのため、下記のようにHTMLのタグを使って、これがタイトルであるという事を示します。
例)このブログのタイトル
<title>ビジネスとIT活用に役立つ情報</title>
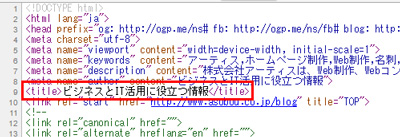
HTMLソースコード
タイトルの他にも、見出しを示す<h>や、画像の内容を記す<alt>など、様々なHTMLタグでWebページの文章構造や内容を理解します。インデクサーがページの内容を正確に理解することができれば、その正しい理解でページ情報が記憶され、検索ユーザーと情報がマッチングしやすい環境を作ることにつながります。
検索エンジンの順位決定「検索アルゴリズム」
検索結果の順位は「検索アルゴリズム」により決定されますが検索アルゴリズムは公表されておらず、順位決定の仕組みは明らかになっていません。
しかし、Googleでは検索エンジンの在り方に対し次のように言っています。
つまり、検索エンジンとは「ユーザーにとって有益な情報を提供する」仕組みです。
検索エンジンばかりを意識してその本質を損なうことなく、ユーザーニーズの高い情報を提供することが大切といえます。
まとめ
- Webページは、検索エンジンのクローラーにより発見され、インデクサーにより記憶され、サーチャーにより検索ユーザーとマッチングされる。
- 想定する検索ユーザーのユーザーニーズを理解して、検索エンジンにその情報を正確に伝えつつ、ユーザー満足度の高いコンテンツを提供することが検索エンジン最適化となる。
この記事を書いた人

- 創造性を最大限に発揮するとともに、インターネットに代表されるITを活用し、みんなの生活が便利で、豊かで、楽しいものになるようなサービスやコンテンツを考え、創り出し提供しています。
この執筆者の最新記事
関連記事



最新記事





FOLLOW US
最新の情報をお届けします
- facebookでフォロー
- Twitterでフォロー
- Feedlyでフォロー